AI Agent Workshop - ReAct Parttern 源码对比, Google ADK vs LangChain
agent框架里的坑,不看源码是不知道的!
Background
很遗憾,ai发展速度太快,很多基于java 做的agent 框架都不支持planning pattern。因此,我们不得不尝试自己实现planner。本文,你将看到
- Google ADK for Python 是如何实现 ReAct Planning Pattern
- langChain for Python 是如何实现 ReAct Planning Pattern
什么是,为什么出现了 ReAct Pattern
原来是,人们对与ai的期待逐渐变高,从简单的一问,一答的模式,过渡到了处理,解决复杂问题的的模式。 从前我们可能只是简单的问ai,特别是home pod
我的手机在哪?
现在,ai agent 能帮助我们解决更为复杂的问题,比如:
看看有多少人在家,给他们的手机发个消息,快来餐厅吃饭!
这样的较为复杂的任务,需要ai 先对任务进行一定的分析,拆分成小任务,通过前后小任务的执行结果,在进行下一步任务。以此而达到解决复杂任务的效果。
ReAct 孕育而生,ReAct 是Reasoning + Action 的缩写。
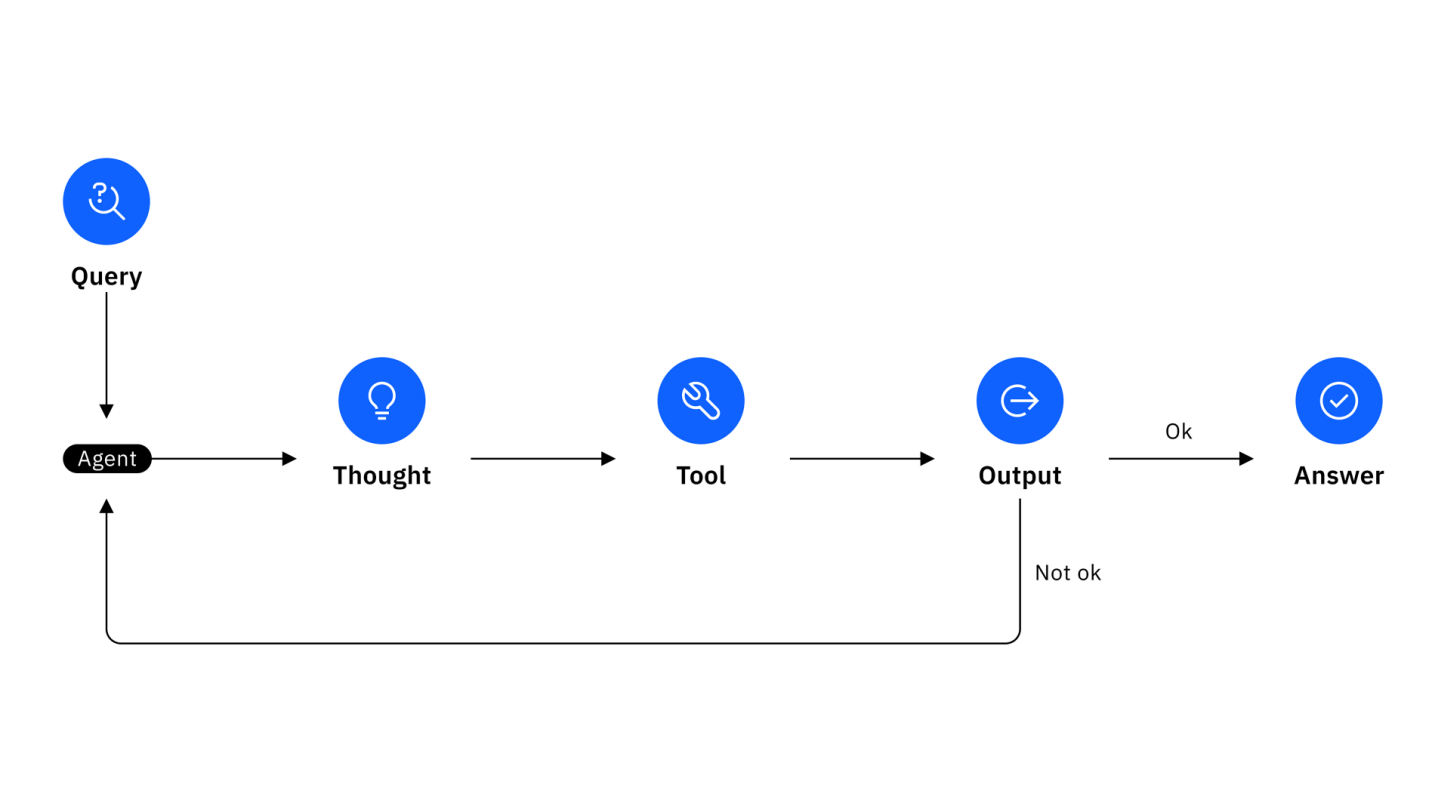
用户问题
↓
/*PLANNING*/ 制定计划
↓
/*REASONING*/ 分析推理
↓
/*ACTION*/ 执行工具
↓
观察结果
↓
/*REASONING*/ 基于结果继续推理
↓
/*ACTION*/ 执行下一个工具
↓
...重复上述过程...
↓
/*FINAL_ANSWER*/ 最终答案
举一个实际的例子来说:
“今天北京的天气如何,适合户外运动吗?”
/*PLANNING*/
1. 首先获取北京当前天气信息
2. 分析天气条件是否适合户外运动
3. 给出建议
/*REASONING*/
需要先获取北京的实时天气数据,包括温度、降雨、风力等信息
/*ACTION*/
weather_api.get_current_weather(city="北京")
/*REASONING*/
根据天气API返回的结果:温度22°C,多云,微风,无降雨
这种条件比较适合户外运动
/*FINAL_ANSWER*/
今天北京天气多云,温度22°C,微风,无降雨。
这种天气条件很适合户外运动,建议可以进行跑步、骑行等活动。
除了ReAct 还有其它的pattern,不再赘述。
Implementation
ADK Implementation
base_agent.py -> llm_agent.py
- 注入和planing 和planner,
- 注入llm flow
base_llm_flow.py ->
- 执行所有processor的run_async方法
_nl_planning.py ->
- override
BaseLlmRequestProcessor:run_async() - override
BaseLlmResponseProcessor:run_async() - 抽象
build_planning_instruction和process_planning_response - 调用 base_planner.py
- plan_re_act_planner implement
build_planning_instruction()andprocess_planning_response()
- plan_re_act_planner implement
react 的核心在于plan_re_act_planner.py重写的build_planning_instruction() 方法和process_planning_response()方法。 在plan_re_act_planner.py的实现里,
- 每次都会检查执行结果,如果planing 还有需要调用tool的时候,就会继续,这里是一个循环。 reasoning -> action -> observation -> reasoning -> action -> observation …
- 当没有再进行任何function call的时候,就会停止,返回最终结果。
1
2
3
4
5
6
7
8
if first_fc_part_index > 0:
j = first_fc_part_index + 1
while j < len(response_parts):
if response_parts[j].function_call:
preserved_parts.append(response_parts[j])
j += 1
else:
break
如果你使用的大模型支持planning,那么就可以直接使用build_in_planner.py. build in planner 就没有循环,只有一次reasoning -> action -> observation. 但是由于llm支持planning,他会一次调用多次tool。
我提交了一个java 实现的pr,https://github.com/leweii/adk-java/pull/1 能够更好的从这个pr里去理解react 的实现。
LangChain Implementation
单看源码,会发现好多类都废弃了。要留意。(截止aug 26, 2025) 其中起决定作用的是:
- /libs/langchain/langchain/agents/react/agent.py
- /libs/langchain/langchain/agents/output_parsers/react_single_input.py
- /libs/langchain/langchain/agents/mrkl/prompt.py
在react_single_input.py 里,定义了prompt,需要llm分析输出结果,并把输出结果放在Observation后。
在agent.py 里,先检查是否有定义stop condition, 如果没有,就用Observation 作为stop condition。
我希望我没看错,引用太绕了。
如果我没读错代码,当我定义agent时,如果定义了stop_sequence = true 那么它就在一次llm request后观察执行结果Observation的时候停止序列输出。
也就是说 langchain 只是实现了简单的一次reasoning -> action -> observation,并没有循环。
Prompt
关于ReAct的实现,都提到了这篇文献: https://arxiv.org/abs/2210.03629 但是这篇文献的时间是10 Mar 2023,如果只是按照这篇文献的prompt 来实现,可能会有些过时。
ADK Prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
high_level_preamble = f"""
When answering the question, try to leverage the available tools to gather the information instead of your memorized knowledge.
Follow this process when answering the question: (1) first come up with a plan in natural language text format; (2) Then use tools to execute the plan and provide reasoning between tool code snippets to make a summary of current state and next step. Tool code snippets and reasoning should be interleaved with each other. (3) In the end, return one final answer.
Follow this format when answering the question: (1) The planning part should be under {PLANNING_TAG}. (2) The tool code snippets should be under {ACTION_TAG}, and the reasoning parts should be under {REASONING_TAG}. (3) The final answer part should be under {FINAL_ANSWER_TAG}.
"""
planning_preamble = f"""
Below are the requirements for the planning:
The plan is made to answer the user query if following the plan. The plan is coherent and covers all aspects of information from user query, and only involves the tools that are accessible by the agent. The plan contains the decomposed steps as a numbered list where each step should use one or multiple available tools. By reading the plan, you can intuitively know which tools to trigger or what actions to take.
If the initial plan cannot be successfully executed, you should learn from previous execution results and revise your plan. The revised plan should be be under {REPLANNING_TAG}. Then use tools to follow the new plan.
"""
reasoning_preamble = """
Below are the requirements for the reasoning:
The reasoning makes a summary of the current trajectory based on the user query and tool outputs. Based on the tool outputs and plan, the reasoning also comes up with instructions to the next steps, making the trajectory closer to the final answer.
"""
final_answer_preamble = """
Below are the requirements for the final answer:
The final answer should be precise and follow query formatting requirements. Some queries may not be answerable with the available tools and information. In those cases, inform the user why you cannot process their query and ask for more information.
"""
# Only contains the requirements for custom tool/libraries.
tool_code_without_python_libraries_preamble = """
Below are the requirements for the tool code:
**Custom Tools:** The available tools are described in the context and can be directly used.
- Code must be valid self-contained Python snippets with no imports and no references to tools or Python libraries that are not in the context.
- You cannot use any parameters or fields that are not explicitly defined in the APIs in the context.
- The code snippets should be readable, efficient, and directly relevant to the user query and reasoning steps.
- When using the tools, you should use the library name together with the function name, e.g., vertex_search.search().
- If Python libraries are not provided in the context, NEVER write your own code other than the function calls using the provided tools.
"""
user_input_preamble = """
VERY IMPORTANT instruction that you MUST follow in addition to the above instructions:
You should ask for clarification if you need more information to answer the question.
You should prefer using the information available in the context instead of repeated tool use.
"""
看得出,google adk 的react prompt 是经过精心打磨(polish)的,
langChain Prompt
官方example 建议我们从这里拉取:
https://smith.langchain.com/hub/hwchase17/react
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
看得出langChain的实现,还是完全根据文献里的短小内容来设置的。
个人感觉这样的实现真的有点随意啊。
除了注入的prompt以外,源码里还有两个例子分别在文件
- /libs/langchain/langchain/agents/react/textworld_prompt.py
- /libs/langchain/langchain/agents/react/wiki_prompt.py
从例子看出,langChain的实现,是基于llm 支持planning 的基础上写的,而且 较为潦草。
最后
对比两者最大的区别就是:
当llm 不支持planning 的时候 google adk支持循环的ReAct Pattern langChain 支持一次的ReAct Pattern
Prompt 不一样 google adk是一个经过打磨的prompt langChain 一个很简化的prompt
其实,一个agent 框架,是否支持各种pattern是一个很重要的因素,众所周知,langChain在各方面的支持都很丰富,生态也较为完善,但是在读过源码后,发现它对react的支持有些潦草,我心里就有些降低对它的评级了。讲真,这就是这个workshop的意义所在,我们希望更加深入的去了解各个agent框架的优劣。
虽然但是或许,不排除等它们运行起来之后,两者之间不会有太大的区别。但是这一切都要等实践之后才能下定论。
ref:
- https://arxiv.org/abs/2210.03629
- https://langchain-ai.github.io/langgraph/agents/agents/#3-configure-an-llm
- https://google.github.io/adk-docs/agents/llm-agents/#planner
- https://langchain-ai.github.io/langgraph/reference/agents/#langgraph.prebuilt.chat_agent_executor.create_react_agent