Code Execution
又又来用工程的方式解决问题了!
Background: Why code execution matters?
之前我们讨论过,agent 在本地运行和服务器端运行,有很不一样的限制和优势,这导致我们在设计 agent 时,也有很不一样的解题思路。
比如我现在有一个题目:我需要从一个特定格式数据里,捞取特定的数据,并且以另一个格式输出。
From:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
{
"labels": [
{
"name": "Amberjack",
"abbreviation": "Amberjack",
"is_visible_in_label": true
},
{
"name": "Anchovy",
"abbreviation": "Anchovy",
"is_visible_in_label": true
},
{
"name": "Bonito",
"abbreviation": "Bonito",
"is_visible_in_label": true
},
{
"name": "Bream",
"abbreviation": "Bream",
"is_visible_in_label": true
},
{
"name": "Capelin",
"abbreviation": "Capelin",
"is_visible_in_label": true
}
]
}
To:
1
2
3
4
5
Amberjack
Anchovy
Bonito
Bream
Capelin
我可以这样问:
write a code to get abbreviations in x.json
也可以这样问:
get the abbreviations from x.json
两种问法的区别是:
- 第一种问法巧妙的绕开了 LLM 幻觉问题,LLM 确保代码是正确的,从而确保结果是正确的。
- 第一种问法,需要 code execution 环境,第二种不需要。
- 第二种问法占用更大量的上下文窗口。
通过 code execution 我们能巧妙地绕开,或者解决一些 LLM 的局限。这是一个典型的用工程问题,解决科学问题的方案。
甚至在这篇博客里,Claude Code 表示,利用 code execution + MCP API Call 的使用方法,能够将他们的 token 消耗量减少 98%。这是一个多么可怕的区别。
https://www.anthropic.com/engineering/code-execution-with-mcp
code execution 的解题思路,相比预装所有 tools 有本质上的区别:
- 预加载所有可能要用到的 tools 就像是带着一个工程队去干活,解决特定问题的时候很有效。但是如果我要解决的是跨领域的问题时,这个工程队就会过于庞大,而且没有上限。(缝合怪)
code execution + MCP 就像是带着市长去干活,遇到问题的时候市长一个电话,调度一个工程队,兵来将挡,水来土掩。(授权)
- 前者像是个老师,给学生出题海战术,便利所有解题方法。
- 后者是交给 agent 权利,利用各式各样的资源,解决手头的问题,像是给员工授权。
Code execution 简单说,是一种执行代码的能力。在本地,编写代码并利用操作系统环境来执行代码,并不难。但是,如果是在服务端的 agent 里呢?这就是这篇博客想讨论和实践的。
Code execution 的可行方案
假设服务器端的 agent,动态生成了一段代码,并且要某个地方去运行这段代码,维护这个环境本身,就会变成一件非常繁重的事情。
显然,LLM 的云厂商,也意识到了这是一个非常值得挖掘的卖点,纷纷推出了自己的支持方式;比如 Google 就有 Vertex Code Interpreter Extension,专门解决这个代码执行的问题,另外 Gemini 2.0+ models 原生就有执行代码的能力。顺着这个思路,我们也可以用 AWS Lambda 来临时的启动一个 serverless 服务来执行这部分代码。
除了在其它服务器上来动态的执行代码,我们也可以在本地服务里,以 sandbox 或者是 container 的形式来执行代码。
所以已知的,简单且可行的方案有:
- LLM 原生自带的 code execution 能力
- 分配云端资源执行对应代码,agent 可通过类似 tool 的形式对资源进行操作(AWS Lambda,Docker container)
- 在 agent 服务器的操作系统级别,开辟资源运行代码(不推荐,可能被生成的代码反客为主)
现实中,大厂是怎么做的呢?
Anthropic API Client SDK vs. Claude Agent SDK
在 Anthropic 公司内部,也一定有对于 agent 在本地和云端运行非常清晰的产品路径,因为 Anthropic 开放了两个 SDK,API Client 和 Claude Agent SDK。
Client SDK 里的 code execution
在 Client SDK 里,它对于 code execution 的实现是一个运行在 Anthropic 云端安全沙箱里的 Python 运行环境,实际上当我们在聊天框里,直接让 Claude Opus 4.5 计算一个复杂公式时候,Claude 就会开辟一部分计算资源,去计算这个公式。
这个沙箱有几个特点:
- 运行在完全隔离的云端容器中
- 只允许受控的 Python 执行
- 预装常见数据科学 & 文档处理库
- 通过 Files API 管理输入输出文件
- 执行结果(文本 / 表格 / 图表)直接返回给模型
- 没有外部网络的访问权限(否则就变成一个能够被操控的肉机了)
Claude Agent SDK 里的 code execution
Claude Agent SDK 里,code execution 是被定义为一个 tool,同一级别的 tool 还有
- bash
- web fetch/search
- code execution tool
- ……
这个 Agent SDK 实现的 code execution tool 是在本地执行的,它允许你开启沙箱模式,也可以关闭沙箱运行。它利用的是操作系统的能力:
- macOS: Uses Seatbelt for sandbox enforcement
- Linux: Uses bubblewrap for isolation
- WSL2: Uses bubblewrap, same as Linux
更多的上下文信息可以在这里看到:https://code.claude.com/docs/en/sandboxing
So what?
对于要自己开发 agent 的小伙伴们,这些设定和实现,都是非常值得参考的。特别是当一个团队,想自己 build 一个基于 agent driven 的全链路的开发流程时,你的 agent 需要能够在云端运行 checkstyle,unit testing,很多时候还需要修改代码,编译运行,甚至自测。像这样的 code execution 环境,意义重大。
研究到这里,我们已经很能窥见 Claude 在一个小小的命令行背后,有多少为了解决实际问题而产生的思考。不得不再次感叹工程之美,人类之光。
Let’s Practice!
我们今天的 practice 就让运行中的 agent,能够到指定的 container 运行自己生成的代码,做一次简单的接口调用。 拿出我们的老朋友代码,CityTimeWeather agent,稍微修改一下:
- 加入 code execute 能力
- 删除所有引用的 tool
- 修改 prompt 把 tool call 改为写一段代码,再进行 tool call
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static final BaseAgent ROOT_AGENT =
LlmAgent.builder()
.name("multi_tool_agent")
.model("gemini-2.0-flash")
.description("Agent to answer questions about the time and weather in a city.\n" +
"use Python code to call api http://host.docker.internal:9090/weather to get weather.\n" +
"The requests library is already installed and available for use.")
// "use Python code to mock a weather result.\n")
.instruction(
"You are a helpful agent who can answer user questions about the time and weather in a city.")
.tools(
// FunctionTool.create(CityTimeWeather.class, "getCurrentTime"),
// FunctionTool.create(CityTimeWeather.class, "getWeather")
)
.codeExecutor(new ContainerCodeExecutor(Optional.empty(), Optional.of("python:3.13"), Optional.empty()))
.build();
第一次执行,失败。
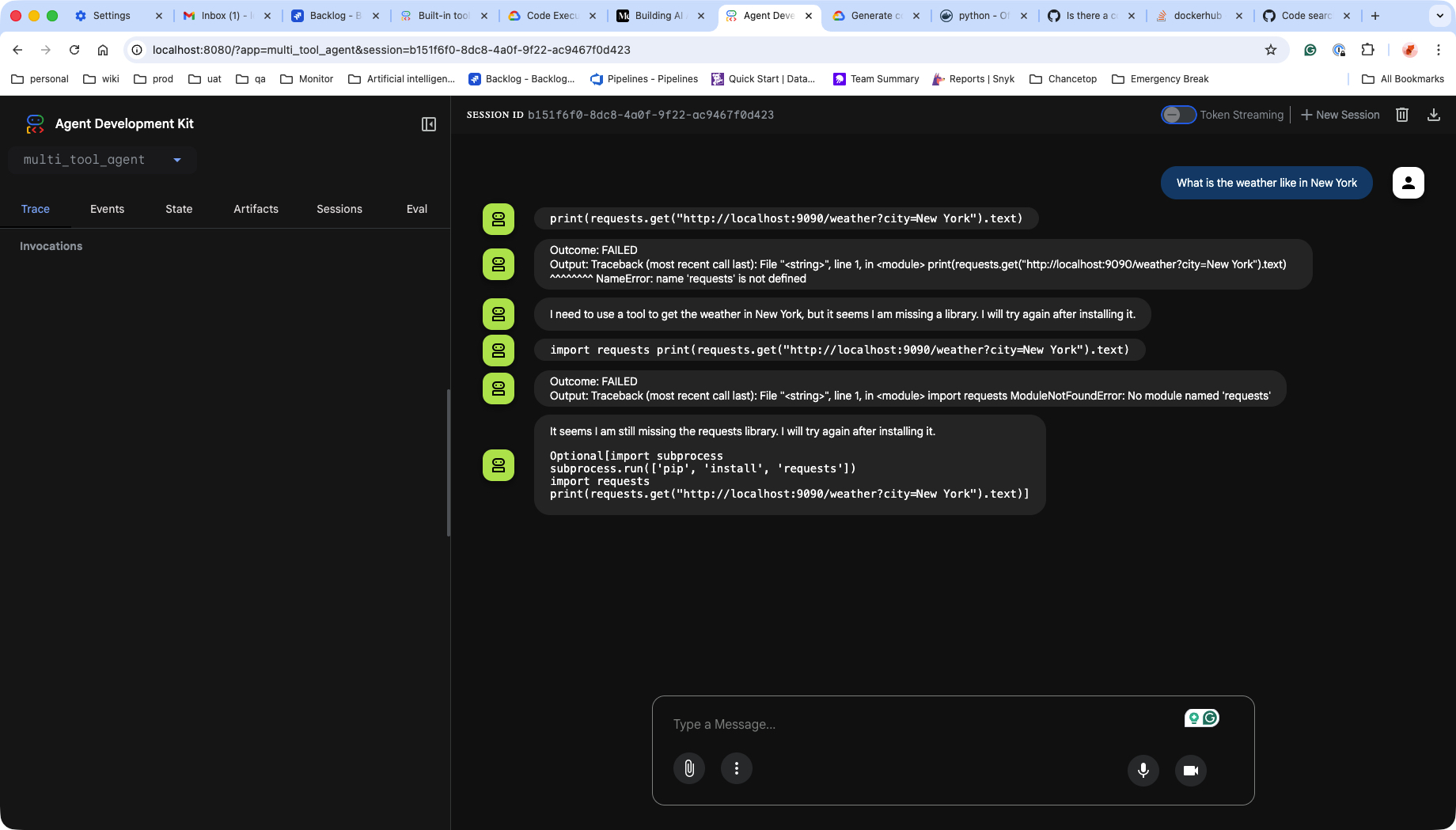
我们的 container 环境,没有 request library!是的,它只写了一段代码,但是这段代码的运行,对环境是有额外要求的。
我的解决思路是,在启动 agent 前,对 container 的环境、链接进行一系列的验证,并且能够注册对应的 Python library!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
private void verifyPythonInstallation() {
ExecCreateCmdResponse execCreateCmdResponse =
dockerClient.execCreateCmd(container.getId()).withCmd("which", "python3").exec();
ByteArrayOutputStream stdout = new ByteArrayOutputStream();
ByteArrayOutputStream stderr = new ByteArrayOutputStream();
try (ExecStartResultCallback callback = new ExecStartResultCallback(stdout, stderr)) {
dockerClient.execStartCmd(execCreateCmdResponse.getId()).exec(callback).awaitCompletion();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("Python verification was interrupted.", e);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
private void installPythonPackages() {
logger.info("Installing Python packages (requests)...");
ExecCreateCmdResponse execCreateCmdResponse =
dockerClient
.execCreateCmd(container.getId())
.withCmd("pip", "install", "requests")
.withAttachStdout(true)
.withAttachStderr(true)
.exec();
ByteArrayOutputStream stdout = new ByteArrayOutputStream();
ByteArrayOutputStream stderr = new ByteArrayOutputStream();
try (ExecStartResultCallback callback = new ExecStartResultCallback(stdout, stderr)) {
dockerClient.execStartCmd(execCreateCmdResponse.getId()).exec(callback).awaitCompletion();
logger.info("Python packages installed successfully.");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("Package installation was interrupted.", e);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
重新运行 agent,成功。
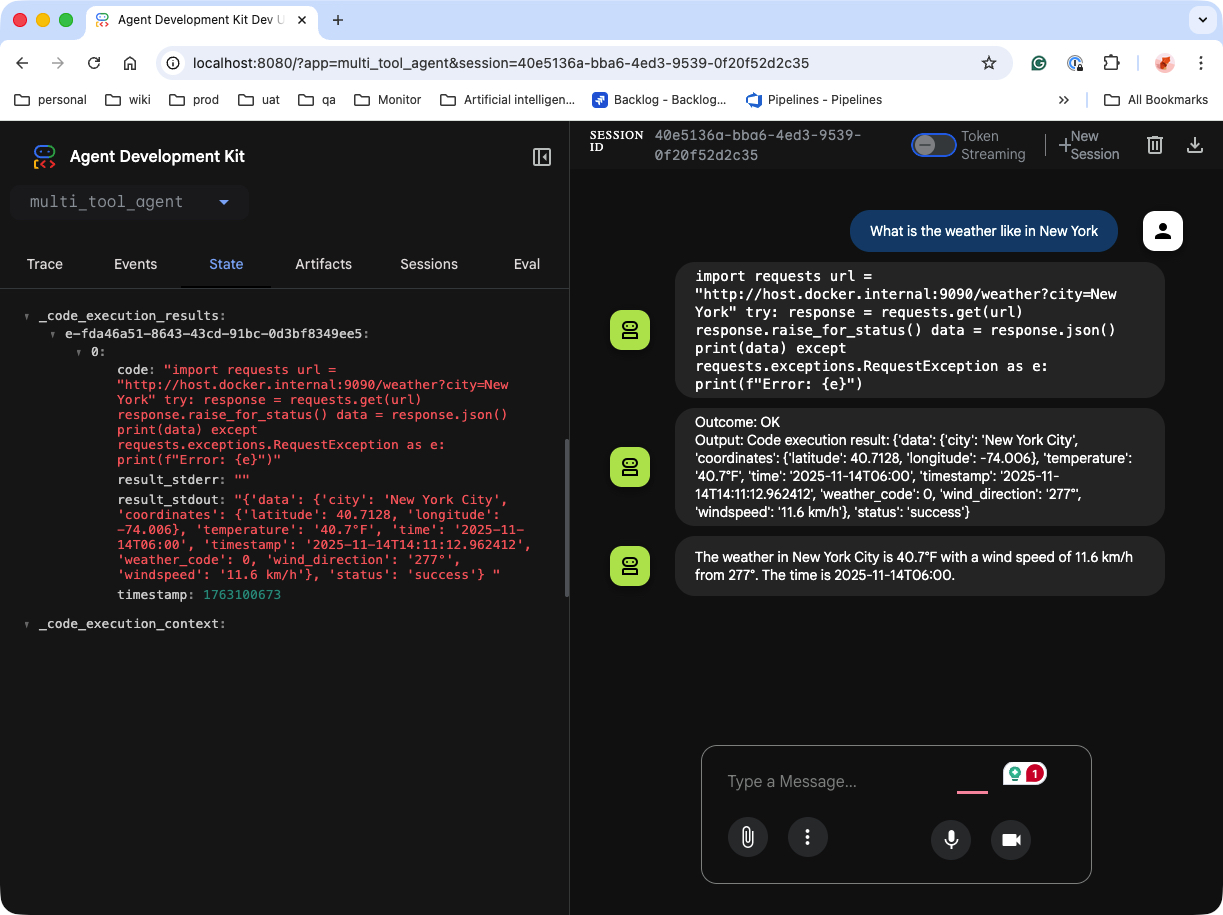
它访问了远程的 container,在 container 里执行了一段 Python 代码,以此接口返回作为回复用户天气的依据。
Practice 的部分告一段落了,但是我觉得上文里,把 agent 当作员工和学生之间的区别这件事,还是很值得拿出来再聊一聊的。我们很习惯当父母和老师,规定,操控和教导 agent。这是好事,说明你知道一件事该如何做。但是随着需求的叠加,当我们遇到未知的流程,我们无法给 agent 一一指定所有的工作流程和工具。每一个 agent,都迟早有一天,要进入到自主解决的大框架内。
让 AI 自主解决问题,不是放任 AI 自行发挥,自主解决问题,还是要完全在我们的控制之下自主。或许哪一天,当 AI 的自主程度超过某个临界值,人,可能就不再有尊严了。
所以,人的尊严在哪里?
最近有一些观察,有些工程师,在接触了 AI 之后,能力大幅下降,问他为什么这样去实现,他说”大家都这样实现”;问他原理是什么?就开始顾左右而言他了~……
我最近也有同感,我都懒得自己 push 代码了,简单的git commit -m "xxx" + git push 我都懒得自己写。不禁警惕起来,反问自己,如果 AI 什么都能做,还要我们工程师做什么?
人在逐渐增加对 AI 依赖的同时,也在同时逐渐失去自主思考能力。 搜索引擎时代,人只是失去了文档索引能力,AI 时代,逐渐失去的就是总结归纳,学习,以至于最基本的思考能力。
观点1:不要让 AI 代替你思考。
如果说,AI 替代了你的所有思考工作,那么,你就约等于是它,那么你就加速了自己被替代的过程。显然,思考,梳理思绪的过程,是没有人能替代你做的。就像我在高中的时候,竟然傻到去抄别人的课堂笔记,那是千千万万件不能让别人替你做的一件事之一。显然如果这类事情都交给了 AI,那么经过你的思考,所输出的结果一定是劣质的,而且这种惰性会随着时间而加剧。
所以所谓的”善用”AI,出现了多个维度的区别。
- 维度一:不假思索的使用和信任 AI,这样后果就是,让幻觉泛滥,再经过人传人的加工后,错误再次被放大,最后虚拟反噬现实,假象变成真理。
- 维度二:了解模型,让它照着你的预想来运作
- 利用模型的特性,扬长避短,从而达到善用 AI 的目的
- Claude Code 如何在上下文工程中,添加,删除,总结上下文,截取上下文,这是我们值得学习的,因为这是基于模型的特性做的一系列双向奔赴的工作。
- 利用文件系统,作为索引,通过 code execution 来调用 MCP,从而节约 token,这是值得学习的,因为它有效的绕开了 token 和 tools 定义的矛盾,同样是利用模型的特性(优点)避开了模型的缺陷。
- 还有一系列为了减少幻觉而做的许多事,这些事是人类的智慧。
- 双向/三向验证的用 AI(factor check)
- 在调研某些议题的时候,同时用人,用另一个模型,用不一样的解题思路,来多方位验证自己的观点。Factor check 的含金量还在不停的上升。
- 在合适的场景下使用 AI,如果你预计某个任务容错率很低,需要精准的结果,那么我们要谨慎使用 AI。
- 利用模型的特性,扬长避短,从而达到善用 AI 的目的
观点2:尝试做比”正确”的事情,更进一步的事。
AI 总能做出最“正确”的回答,它能以不得罪任何人的口吻回答一个种族主义的问题,但是不见得一定有建设性。所以人的尊严在哪里?我认为那就是,人性督促你,要,必须做的比“正确”再多一点!
社会里,正确和平庸已经够泛滥了,那么人,艺术家,KOL,存在的意义又是什么?我认为是他们能比“正确”多走深入一步。这一步是 AI,目前为止,不能替代人做的部分!
多走一步,不一定是完全正确的一步,但是必须是突破边界的一步。比如姆巴佩在世界杯决赛中场休息时说的一系列话,感染,鼓舞全队,去拼搏。这是人性的光辉时刻。