个人/企业知识库管理框架
LLM 时代的个人分身,从个人知识库管理开始。一个广泛的焦虑是,如果我有一个 agent 分身,那么它就能替代我。既然如此,我为什么还要努力打造一个个人 agent 呢?
为什么
为什么我需要一个 agent,替代我?
一个数字化的个人有什么意义?
我们(人类)花了那么多时间(互联网诞生到今天)把绝大多数的企业流程、表格数据化;我们又花了非常多时间(移动互联网流行至今)把个人信息、健康指标、行动轨迹数据化;
不为别的,只是为了数据化的信息能够解锁巨大的可能,比如预测用户行为,比如分析用户喜好,比如打造只属于你的内容推荐。
到了人工智能时代,我们可以再往前走一步,将一个人的想法数据化,利用他每天接纳的知识,输出的文字,开的会议,每一个思想上的小动作,我们就能很粗略地拥有一个人的思想分身。
我敢断言,个人思想(知识)的数据化,让我们能解锁的能力绝对是爆炸性的。随着在个人场景里,AI 被挖掘的使用场景爆炸性增长,人类对 AI 的需求也会从企业走向个人,粗略估计一下,又是一个十万亿以上的市场 :)
简单说为什么,那就是一个能够自我复制的”我”,就是为什么我需要一个 agent 分身替代我的原因。
偏题了,如何搭建一个自己的知识管理框架,才是我今天最想讨论的话题。这是拥有一个 agent 分身的先决条件。
替代何时会发生?
是的,他能替代你做很多事,但是他不能完全替代你,不能完全替你承担责任,不能完全作为你下决策。从各种角度看,它都是你的三头六臂,empower you,而非 replace you。
替代何时会发生?总之不是现在。当法律健全,模型能力大幅提高(在计算、记忆、伦理判断、思辨能力方面都高于,或者远高于人类),知识库 100% 完善,当少数派报告的时刻到来,人,才会被完全替代。
采集思想
全世界都知道,AI 时代,任何企业、任何个人的护城河,就是数据+领域知识,下沉到个人,那就是你的思想,你每天产生的数据:网页浏览记录、聊天记录、代码、文档、照片、截图、视频。
每个人的当务之急,就是把以往所有的数据,全部系统地归拢到一个知识库里。
第二个就是不停地把你的思想,用文字文本的形式表达出来,表达的越多,越准确,这个 agent 基于你的知识库能做的事情,就越接近你。特别是你的经验和专业知识,以及对某件事的态度、底线和原则。
在科幻电影里,大多这样的过程是扫描你的大脑神经元。现在,我们还没到那个程度,我们要从文本开始,因为这一切都是基于 LLM(大语言模型)做的尝试。
实践
理论的东西讨论的太多了,我今天这一系列的探索,是源于探索一套企业级领域知识管理平台的初衷。作为企业,总是希望每个个体沉淀下来的经验、业务知识、数据,都能成为公司价值的一部分。那么源于这个初衷,我们需要满足每个公司个体工作记录的需求,一个本地、云端的文档同步机制,一个能够聚拢和归纳知识的大脑,和一个可靠的高效的记忆单元。
所以流程上看,一个知识库,需要做到这样一个流程:
- 用户个人层级的沉淀 -> 在本地进行预加工
- 同步本地知识到云端
- 云端Agent 对所有人的知识进行抽象聚拢 -> 形成可复用推广的知识库
- 通过sync layer 推送到每个用户本地
- 在新的项目或者新的工作中,应用这些知识
知识本身在这个流程里达成闭环,如果有必要,基于聚拢之后的知识库,我们还有无限种可能。
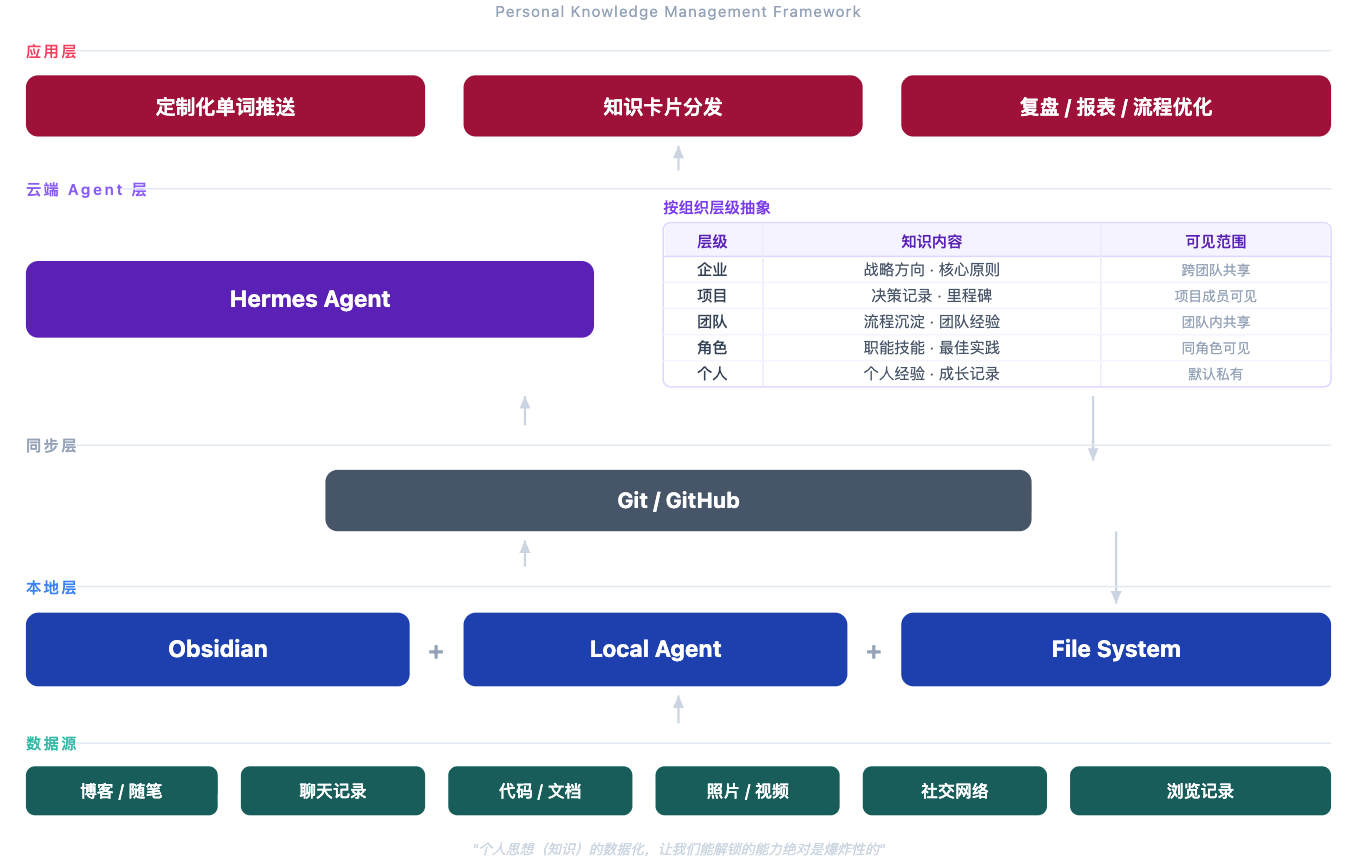
这里我们就有四层知识库组件:
- 本地: a. 有一个interface 负责管理知识。 b. 有一个agent,负责归纳聚拢知识。
- 云端: a. 运行着一个Hermes agent,提供应用层的agent 能力。
- 同步层: a. 负责将知识库,在各个终端中同步。简单做,目前我就是用github。
- 应用层: a. empower 知识库的知识,让他在各个场景应用。
真正的工作流可能是更为复杂的,但是抽象的看,简单的看可以就是这三层的组件。
画个图,就是这样的:
搭建这样的个人知识库,你需要考虑的事情有:
搜罗你的数据
一个粗略的个人知识库,就是一堆文本+附件,这些东西就能代表你在某件事上,各个维度的态度。
于是我找出了所有我能拿到的关于自己的数据:博客、随笔、聊天记录、邮件、图片、视频、社交网络 moment。
从各个角度去归纳这些数据,于是我有了一个基于文本的,最基本的个人数据库。
本地 agent 层
此时此刻,我的工作流程,已经高度绑定了 agent,小到我的个人博客 review,大到任何项目的启动,触发点都是一个新的 Claude Code session。
在这样的背景之下,我会让我本地 agent 自动记忆和归纳所有讨论的要点,让它变成我知识库里的一部分,假设一个项目从头到尾都是这样跟踪维护下来的,那么我的文档就能体现整个项目的前因后果,各种决策的始末,所有的会议纪要和录音。
这样维度的项目跟踪,在从前是完全做不到的。我甚至都已经在幻想,当我们有完整的数据之后,我们能借助 agent 做复盘、做报表、做流程优化。
本地 interface - Obsidian
本地 interface 我选用了 Obsidian,不仅仅是因为我一直在用这个软件,现在大家青睐它是有一系列原因的:
本地文本,易于检索
为什么云端的文本,例如 Notion 不易于检索?因为网络通讯的代价太大,搜索接口不透明,返回数据结构复杂,HTTP 请求消息体有上限。种种原因下,最适合做知识库的形态,还是本地文本。
双向链接+检索
Obsidian 天然支持的双向链接,让它在你的本地,构建了一个简易的图数据库,不同的知识之间构建了千丝万缕的联系,就像你的大脑。
Obsidian CLI + Skill
Obsidian 团队敏锐地意识到,AI 高度依赖本地执行的能力,早在一个月前,就发布了 Obsidian CLI 和对应的 skill,从这个视频里,我们能看到 CLI 支持的各式各样的命令,connect、health check、randomly provide 一些灵感。许多很有意思的用法都可以从这个视频里看到。
https://www.youtube.com/watch?v=6MBq1paspVU
知识持久化与同步
早在一年前,还有人或许会心存疑虑,如何管理好知识是一个很大的问题。
知识录入不难,难的是维护和更新管理。我们假设知识进入到系统的一瞬间是一个节点,往后的时间就是它的维护成本,如果这个流程过长,复杂度过高,那么知识被分发到各个终端的代价就越高。
目前很多平台,都是第一性原理+剃刀原理,如果是文本搜索就能解决的问题,绝不引入更复杂系统。
但是长远看,这是一个很值得行业探索的问题,目前并没有一个一致的看法和最终的答案。但是我们能肯定的一点是,知识,即文本。至少目前是这样。
如果说,目前的情况下,知识,即文本这个观点是成立的,那么我们就一定要最大程度地利用所有的基于文本的基础设施,比如 git,比如文档管理工具,Obsidian、IntelliJ、Notion,当然最重要的是 LLM 本身,就是基于语言而训练的。
所以文本同步最简单的方式就是 git。
云端 Agent 层
这一层在做两方面的工作:
- 归纳总结抽象知识
- 知识的对外出口
归纳总结抽象知识
个人
知识的表现形态,既需要人可读,也需要机器可读,中间势必存在一定落差。
我以一个 cron job 每天半夜帮忙利用 LLM 的能力,分析每天新增的文档。
这是因为我个人的工作习惯,我总是在 inbox 里不停地输入各式各样的想法,极少地去归拢它们。最后草稿终究还是草稿,缺少了自然生长的过程,草稿缺少了一个能生长成的环境,如果有条件,这样的过程一定是人来做,手动做,最合理。
对于企业来说,这一层工作一定是由一个云端 Agent 来执行的。
对于个人来说,在这一层里 agent 要做的事情,做到什么程度,都是因人而异的,高度绑定每个人的个人工作流。
组织
从组织的角度来管理知识的话,协作的人、知识的量级、层级的深度,都与个人知识大不相同。
- 每一个知识的更新,都需要更新海量的现有知识,毕竟文本不能像代码一样很容易地被调用方识别出来。
- 多人协作的场景下,有些知识是个人的,有些是组织的,这些东西都应该被模型识别到,并且被提炼抽象到上一层。
总之
云端 Agent 层,对于个人的知识管理来说,是可以忽略的层。我完全可以把它当作本地 PC 里的一个 cron job 来归纳一切。但是,如果你要基于这个知识作出一些应用的场景,就另当别论。下个重点我们可以继续讨论。
但是对于企业来说,对于多人维护的知识库来说,对于要 leverage 个人知识库、开发各式各样应用的人来说,这一层无疑是不可或缺的。
知识的对外出口(应用)
当你拿到知识了要做什么?这就回到了第一大点,为什么的话题上了,理由很简单,信息化的数据可以被系统利用做非常多事情。
我曾经幻想,自己的手能插入到电脑的接口里,直接照着我的想法构建系统,类似 DC 漫画里的钢骨(Cyborg)。现在,你的 agent 就具备这样的能力,它能在虚拟层面,照着你的想法,不间断地做任何事情,有必要的时候还能启动多个自己。
我已经基于这样的知识库 build 了一个定制化单词推送系统。这个系统运行在我的 Hermes Agent 里,它会每天检索适合我的单词,推送到 Slack 上。
设计这个系统的初衷是,agent 逐渐强大,我要用 agent 来回馈我的真实大脑,另外源于我们的黑客松 idea,让知识主动地来找你的初衷。
这样的推送,就消除了打开任何背诵软件的负担,知识主动跳到你面前,让你掌握它。
这样的系统里,单词库是绝对定制化的词库,对个人教育来说,也更有机会做到因材施教。