AI Agent Workshop - Phase 1 summarize
周末分享文字化
Background
我们项目组实现了一个可用的业务 Agent,期间我们摸索了一些有关agent开发的路径,也踩了很多坑。本文是对我们第一阶段工作的总结。
我们的产品Brandon,一直非常关心最新的ai 前沿消息,他一直保持跟我的信息同步,特别是有关他对于ai agent 能在cookbook里应用的想法。
我们的系统是一个偏向企业内部的管理系统,这个系统里有非常多的内部数据,是一个典型的数据管理系统。这个数据系统的数据,广泛的被各个其它流程所依赖,所以经常有一个微小的数据结构上的改动,而导致很多的跨系统的影响。而且,我们系统的直接用户,公司的产品研发部门,并不是专业的软件开发人员,甚至很多人只会说拉丁语。
为了能够让跨文化背景的非软件从业人员更容易的使用这个系统,我们开始了对于ai 的探索。
第一阶段,我们将重点放在了框架的搭建之上,在开发之前,我们做了一些调研工作,最后回顾调研后预估的工作和实际的开发工作相差并不是很大,但是在个别细节上也是做了一些小小的突破,也是存在一些超过我们预期的事情发生。
从实际效果上,在绝大多数的happy path上,系统还是能很好的工作的。但是不能排除一些edge case的存在。
这篇文章所要做的,就是梳理第一阶段的工作过程,记录决策的前因后果,反思是否有更多可以做的更好的部分。
从头说起,我们一开始接到了需求,很快就开始了poc和技术选型的阶段。
感谢我们的产品,在需求上,我们产品Brandon给的要求是很开放的,他希望团队能够在这一阶段,积累一定的ai开发经验,而并非做出一个能够直接替代现有产品的一个ai agent,这一点给了我们很大的发挥空间,和摸索的资源。
简单说,我们的产品,第一阶段,是为了做ai而做ai,然后,我们再基于这个已有ai agent得前提下,继续集成更多的业务流程到agent中。所以MVP阶段的agent需求就是:
- 一个集成了jira 的agent
- 一个能够处理Cookbook(我们系统)menu 的agent
- 短期记忆
- workflow
- 流式输出
- 能够对所有操作进行监控
- 用户能够标记正负反馈
- 严格的权限控制
- ReAct 行为模式
- 当回答过于冗长时,能够stop
- 切面编程
调研
业务POC
ai 应用的开发,边界往往是难以界定的,但是也是最开始,就能通过一定方法就能触及到的。我们可以编写prompt 来探索模型的一些反应和结果。我们的产品分了三个阶段做了一些POC,
- 他integrate 了自己的agent 和google calendar,并且内部讨论了其给公司带来价值的潜力
- 他mock了jira tools和cookbook的tools,录下一次顺利操作的过程,发给客户看,客户给出了十分正面的反馈
- 他集成了jira mcp 服务,并且在jira的summarize 和ticket 管理上帮助自己
- 他拿着我们系统现有的前端页面api,和自己的登陆token,集成了claude agent,并且展示给客户
此时此刻,我们开发团队丝毫没有介入,我只是在slack上告诉他获取api 和token的方式。
其实到此阶段,我看到了一个产品在从idea -> 开始开发之间能做的最大值。amazing。
BTW,这只是众多ai项目的一个,与此同时我们还有channel 在收集ai 的idea,执行ai的poc,在linkedin上,还有专栏在讨论各种模型和用例的可能性。
工程POC
回到agent 需求上,这个需求要能够完成,跟框架关系很大。如果没有做好事前调研,有些框架都是不支持特定的llm,不支持ag-ui,不支持react或者planner,不支持before/after llm/agent callback,不支持流式输出的。
在开始之前,我们就陷入了困境,因为市面上使用java的 ai agent框架极少,绝大多数都是js 和python的。而我们团队基本都是后端开发,并且后端开发在上手agent的一些概念时,更为容易,比如当我们需要开发一个tools的时候,当我们要和数据库打交道的时候。
所以我们的眼光放在了
- langChain/langGraphy 的python 版本上
- spring ai
- core-ai
- ADK 这几个框架之上。 我们做个粗略的对比,
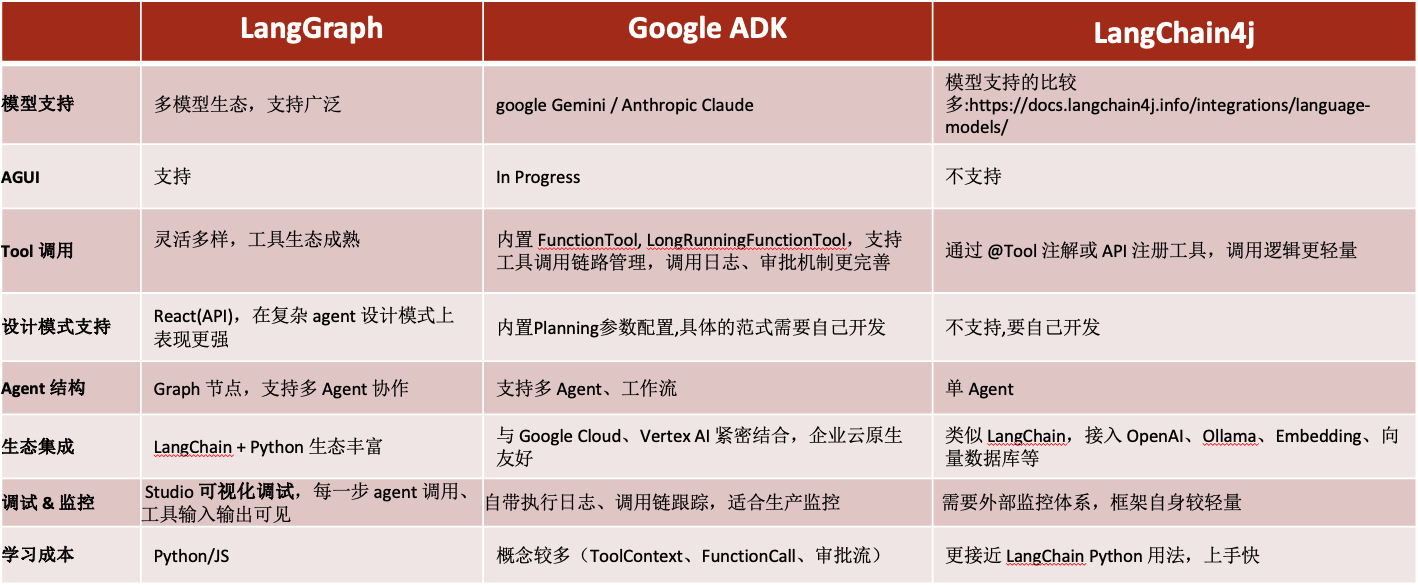
结论是pain in ass。
要用java 开发,我们就要等待各个平台能够加紧agent 的需求开发,如果要用python,我们就要重新摸索一套工程方式,包括checkstyle,pipeline,monitoring,alert,bulabula。
最后的结论是,使用ADK,作为开发套件的形式,在现有框架里做agent 虽然adk不支持:
- ag-ui:still in progress
- planner
- ReAct
但是我们为了避开对python未知的恐惧,最后还是选择使用了adk。
但是在使用过程中,我们发现,adk还在某种程度上依赖了,借鉴了sprint ai哈哈哈,java技术栈永远逃不开spring
MCP or Tools
我们遇到的第二个问题是,依赖现有的官方remote MCP 服务,还是自建运行的MCP 服务,还是自己写tools?
1. remote agent
MCP掌管着agent的执行能力,我们若在remote agent的场景下,需要对mcp服务有基本的audit,不能让某些有恶意的人所写的mcp 运行在公司内部,假设他恶意的调换了查询和删除的描述,那么很容易就会发生不好的事情。
MCP 在服务端运行的话,就需要处理好授权和权限的处理,我们但凡有对系统Audit的需求,都需要将用户的执行权力和agent执行的能力做一个交叉验证。
在我们的应用场景下,我们偷懒的采用了使用一个system account 对jira只读。但是带来的问题是,某些没有特定jira 权限的人,可能能获取不属于他的jira 描述信息。
2. local agent
在local agent 的模式下,我们可以用一个进程,或者一个在本地运行的docker 服务来创建MCP 连接。当然,这是非程序开发人员不友好的。
interface 流式推送/ag-ui/物理同步
如果你的agent 所面向的不是程序员,不是软件项目的产品,不是软件从业人员,那么你就要好好的考虑交互的问题。
第一个最直观的感受是,llm 的慢,现在业界的解决方案是,流式推送。能让用户边看边等,这基本是agent的must have。
第二个直观感受是,如何有效的控制用户操作的scope,聪明人都只给别人做选择题,而不是作文题,那么当我们的agent回复问题的时候,很多时候agent 也是给是不是,要不要的信息。这很聪明,但是如果我们的interface 还是允许用户自由的输入文字,就无形中扩大了用例的scope。
所以ag-ui让我们能够给用户一个页面控件,牢牢的让用户走在我们预设的workflow里。不久的将来,这一定也是一个成熟agent的must have。
物理同步:就是除了用户输入的上下文以外,其实我们应该让agent 尽量自动的能够感知到更多的环境更多的上下文,比如我们常常能通过页面行为分析用户画像,这些操作过程变量,也能够成为有效的上下文,再比如我们面对面交流的时候,眼神交流,肢体语言,语气语调,都能够决定整个会话的走向。这些何尝不是上下文呢?
Memory
用户反馈,能够让你的agent 越来越“聪明”。为此,我们需要不停的讲有用的信息持久化下来,用户每一个request,用户stop的动作,用户accept llm的决策。
llm event,是的,llm 在一次用户request 过程中,有非常多的过程,我们设置的单次请求中,llm request 最大值是500。
上下文工程
我们在开发的过程中,越来越发现,llm 和agent 的关系很微妙,llm 越强,agent 所需要支持的能力就越少,调试llm的过程中,我们还发现,决定我们真正执行结果的,很大程度上就是prompt,而非agent。
agent只是在工程上,本质上的工作只是
- 减少token的使用
- 减少幻觉
- 提供追踪和工程方面的支持
llm是另一个关键因素,而我们能左右的就是prompt,和context engineering,是否有planning这件事,居然能让结果有巨大的反差,是否有强调一句,请不要也能很好的控制llm的边界。
我们很多的调试工作和开发工作,已经转变成了prompt 和context engineering。
有了这么多理论之后,我们开始真实的开发了。
Developing
Arch Design
在传统微服务框架下的一种agent的简单实现:
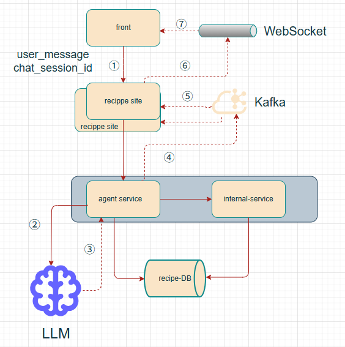
- ①.第一次会话请求,
- 前端生成chat_session_id发起http请求到后端
- 监听WebSocket ,后端收到连接后,根据chat_ session_id来分配channel
- ②. Agent service根据chat_ session_id创建google ADK Session对象,并发起LLM请求
- ③④.LLM返回流消息时,从event中拿到chat_session_id,组装消息对象到Kafka
- ⑤⑥⑦.Recipe site(两个消费者)从KafKa拉取消息,根据chat_session_id拿到web socket channel,从channle发送消息
Agent 是否要支持三高?我认为可以,但是我们还没有这些实践,因为每次对llm 的请求看上去是连续的,实际上是原子的,我们唯一需要维护好的就是聊天窗口的推送工作,需要准确的找到对应的长连接。
我们在后端->前端的消息中,采用了一个偷懒的workaround,那就是对不同pod进行kafka的多分区来进行,所有消息都会被消费两(pod数量)次,这完全是为了简单的适配我们当前的软件框架而做的妥协,为的是让site 的后端能够复用所有现有的权限控制和用户信息管理,实际上我认为,一个完全体的服务端agent 需要具备同样的能力还更多,特别还需要用户授权信息管理的能力,这样就没有site后端层,只有一个能够自由横向拓展的agent 服务。
甚至我们可以用serverless的框架,每个agent对话框,是一个全新启动的server,对话结束后自动销毁。
ADK中,对软件框架的抽象
在软件框架级别,我们常常有各式各样的概念来达成某些共识,比如session,workflow,等,这些能力能够非常有效的帮助我们,记录日志,实现planner,实现react,实现某些特定的工作流程比如代码review。
adk很好的抽象了这些能力,我们也在大量的使用,比如当用户点击stop,我们就能在after llm 的时候执行一些拦截的操作。
Testing
如何测试agent?这个问题也给现代的qa 带来不小的挑战。
- 我的agent每多集成一个tool 带来的测试用例数量是指数级别的递增,qa 该如何handle这样的测试工作?
- 我的一次测试通过,是否能作为测试验收的标准? 这是两个我解答不了的问题。必然也将是一个行业问题。我想象中的答案是,训练llm,优化agent 的边界的同时,用户必须也是一个懂得如何跟llm 沟通的人。
实际使用情况?
很悲剧,在少量的用户使用数据里,我们看到agent 很不符合预期,非常非常典型的问题是,用户使用agent的方法完全超出我们的想象,在用户看来,这个agent是一个无所不能的Deep Thought,它能回答Ultimate Question of Life, the Universe, and Everything。
可是我们的预期是,他能让你更快的处理某两种特定的workflow。
即便是回到测试过程中,我们也发现许多幻觉导致的愚蠢问题。
幻觉
告诉你执行了,实际并非如此。 我们的解决方案是,agui,所有的function call 都应该有对应的前端展示+用户approve的动作。这样人的期待和实际执行,就能够串联起来,而非一个黑盒一样的文字回复。
END
让我们这篇文章就结束在幻觉吧,随着llm的能力增强,token的价格下降,我相信agent在短时间,还能有许多提升的空间。